- If your pipelines produce data in Parquet, you can now bring it directly into Sift.
- Once that data is inside, Metadata, a new Sift feature, ensures it can be organized, managed, and easily found later, making reviews more automated and efficient.
- From there, Explore v2 (Beta) becomes the place to work, transforming Parquet data into insights. Now, in Explore v2 (Beta), with Live Mode, Sync Mode, and Views, teams can track signals in real time and uncover root causes faster.
New: Explore 2 (Beta) expands with Sync mode, Live mode, and Views
- Overview: Explore 2 (Beta) now expands with Live mode to stream data directly into the workspace and Sync mode to align a multi-panel view containing different Channels. When Sync mode is active, zooming into one panel automatically adjusts the others to the same time range. An early implementation of Views is also available in Explore 2 (Beta): you can apply Views created in Explore 1, with support for creating and editing Views planned for a future release (in Explore 2). These updates build on the foundation of Explore 2 (Beta), which delivers speed, precision, and control for high-frequency telemetry analysis.
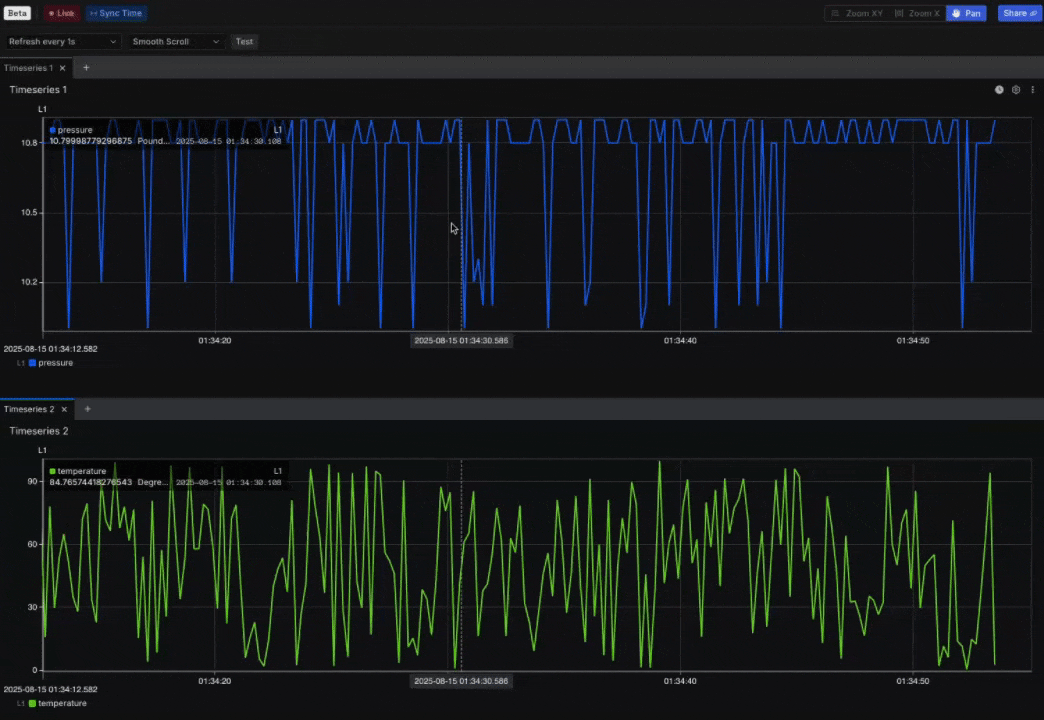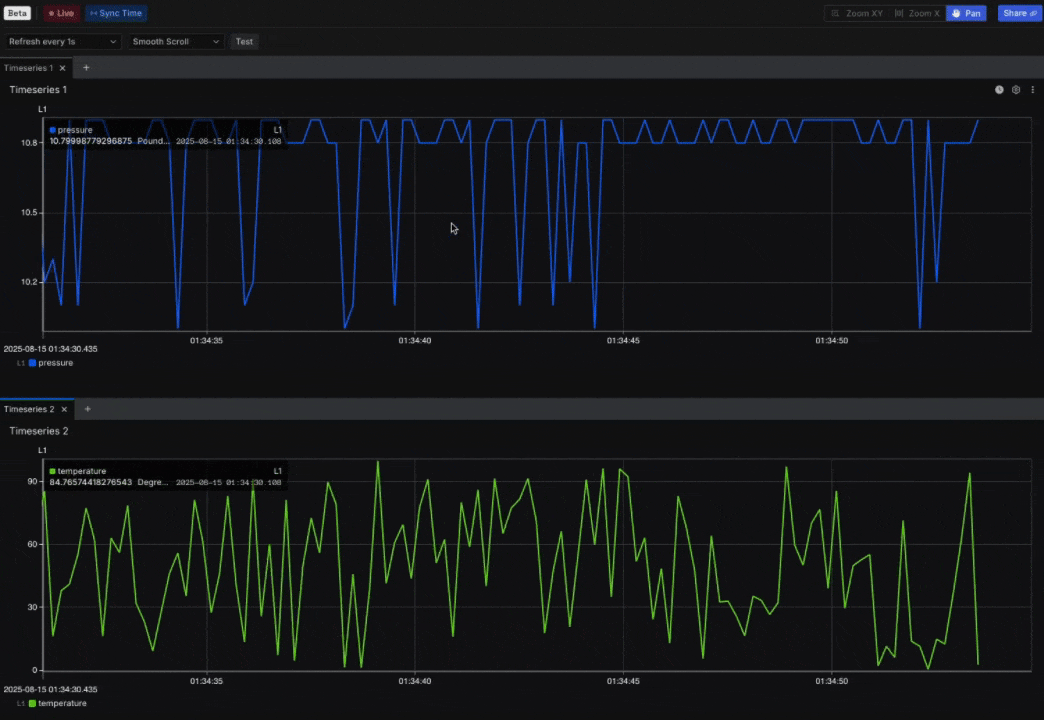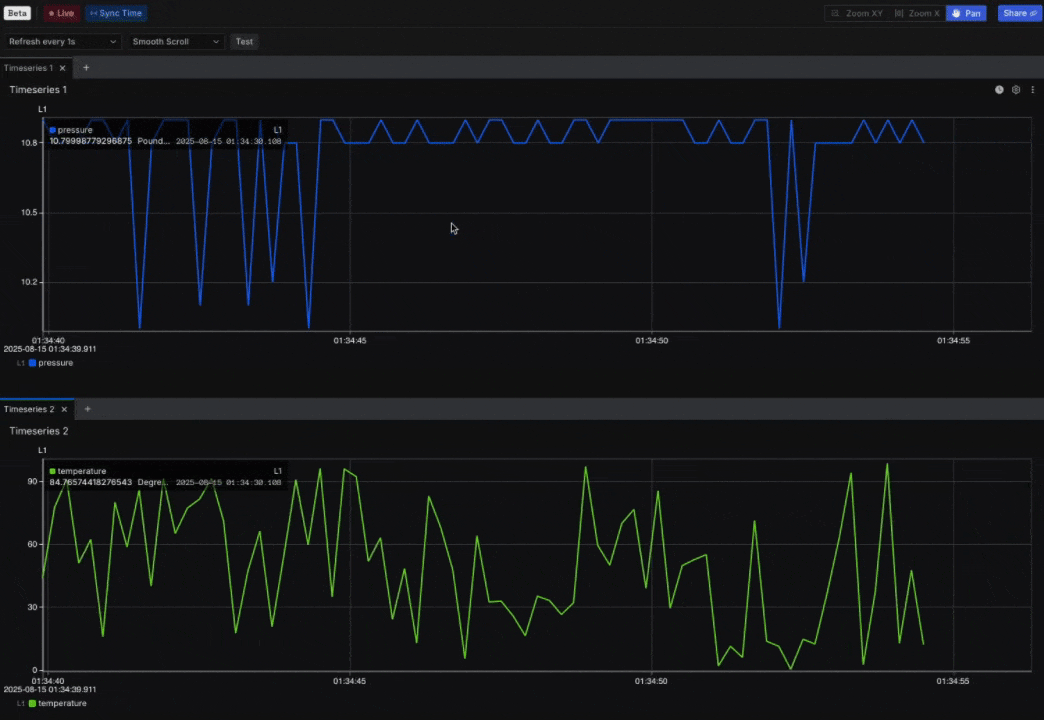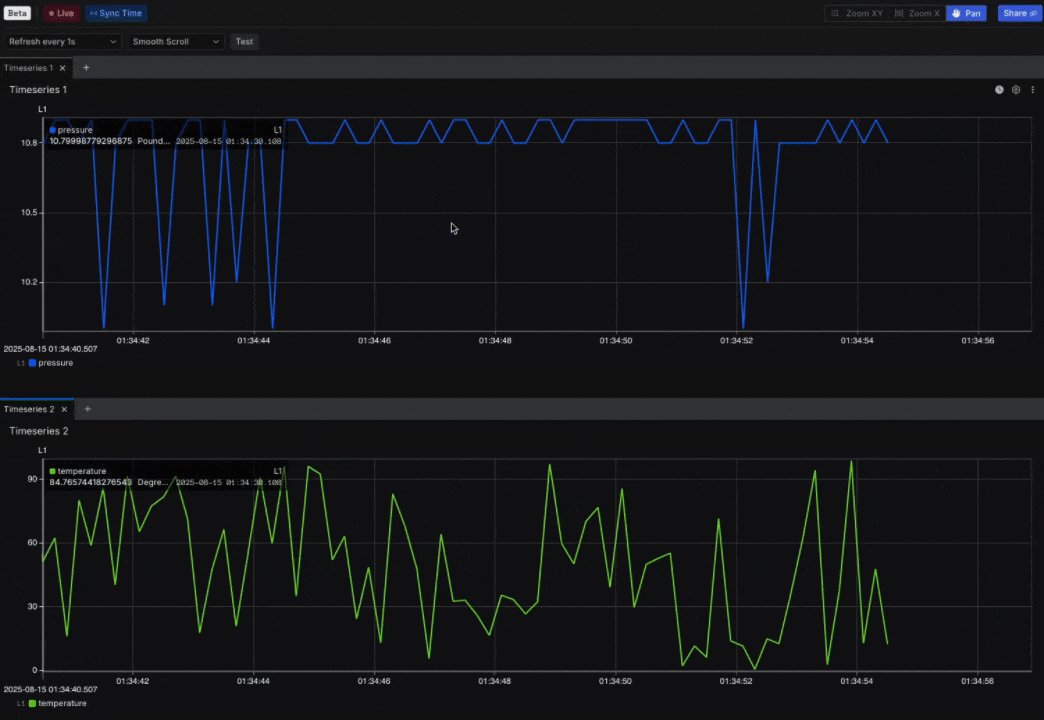
New: User-Defined Metadata for consistent organization/filtering across Sift resources
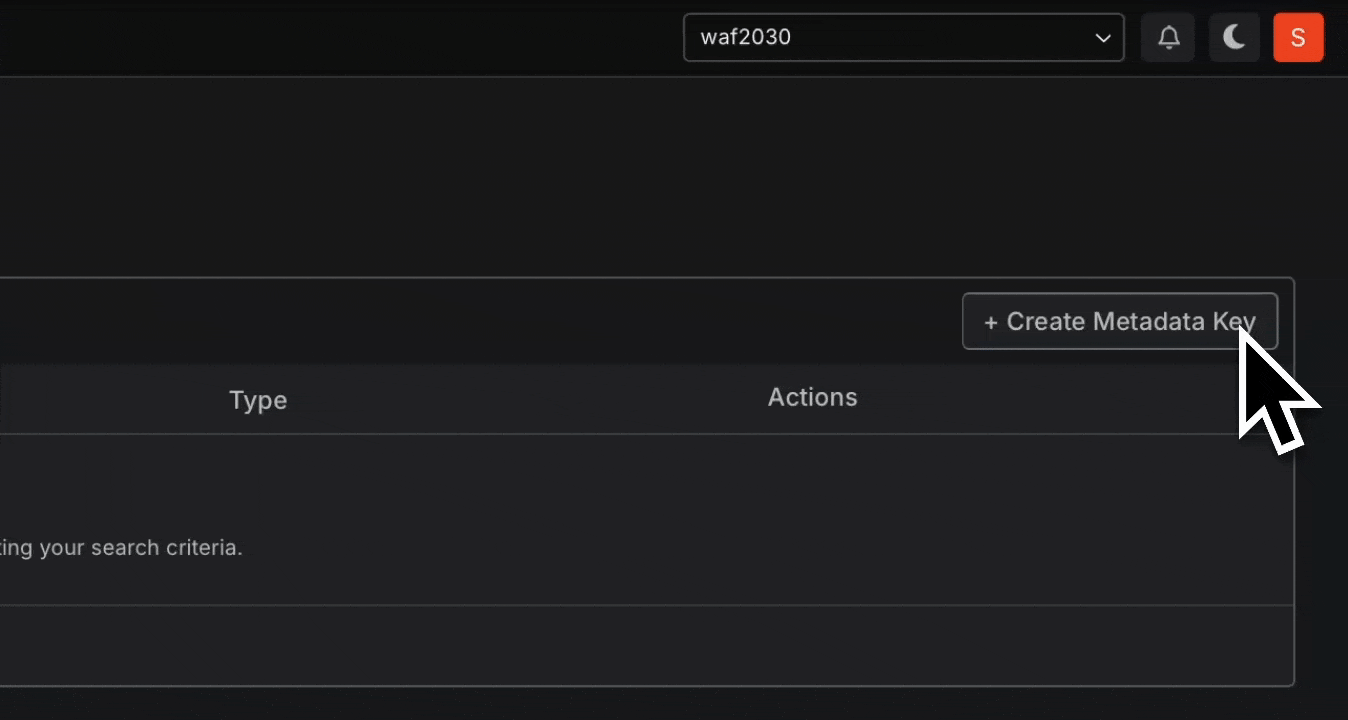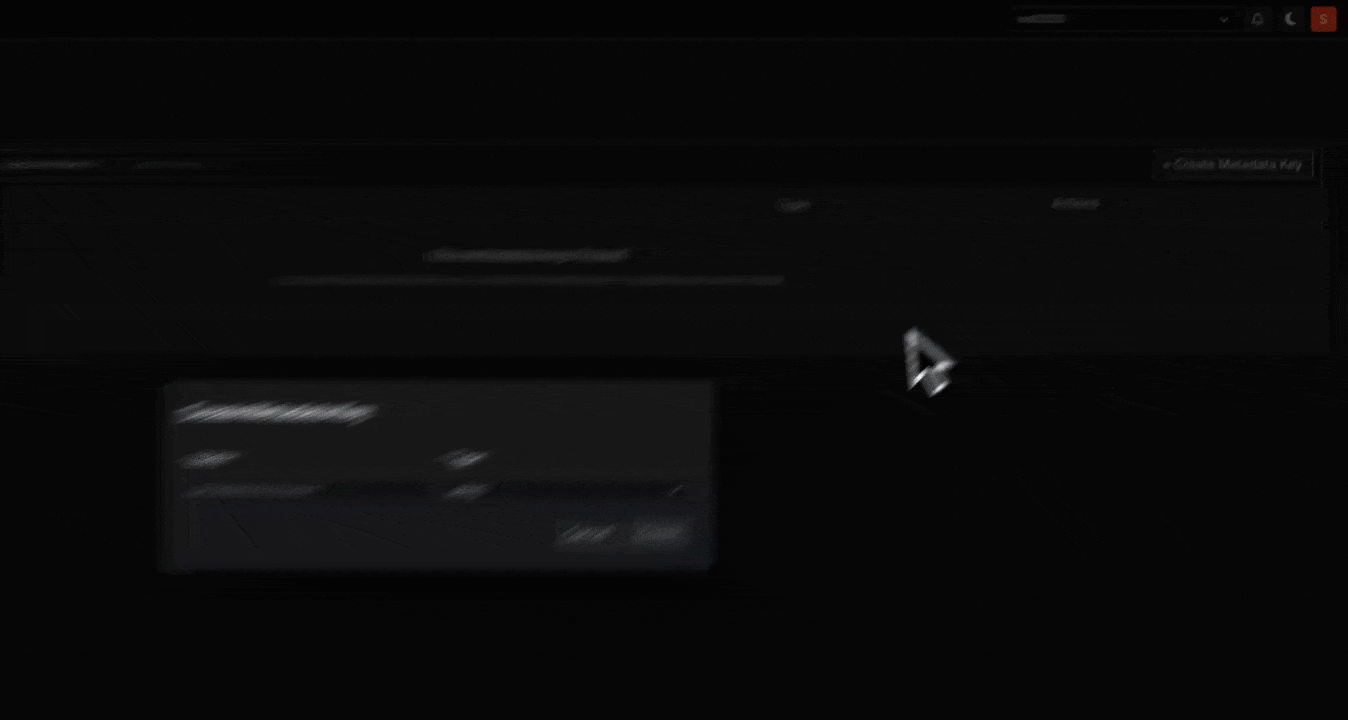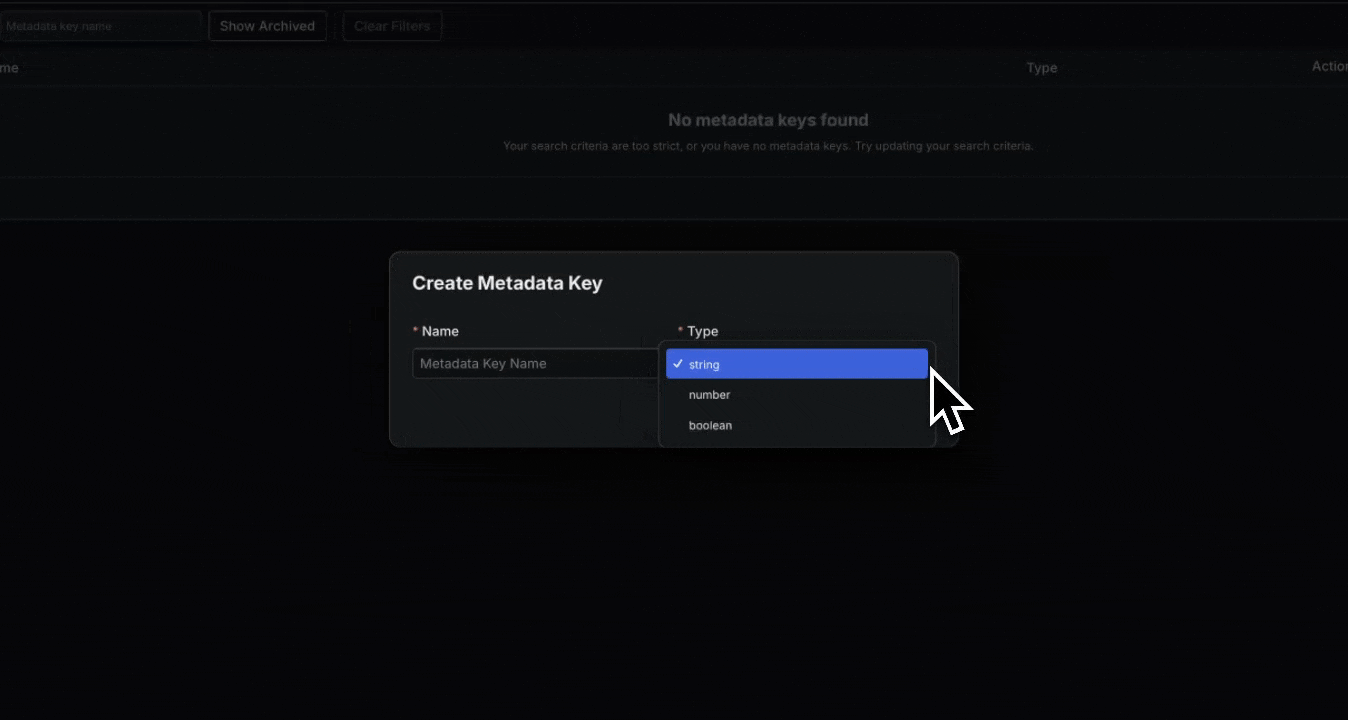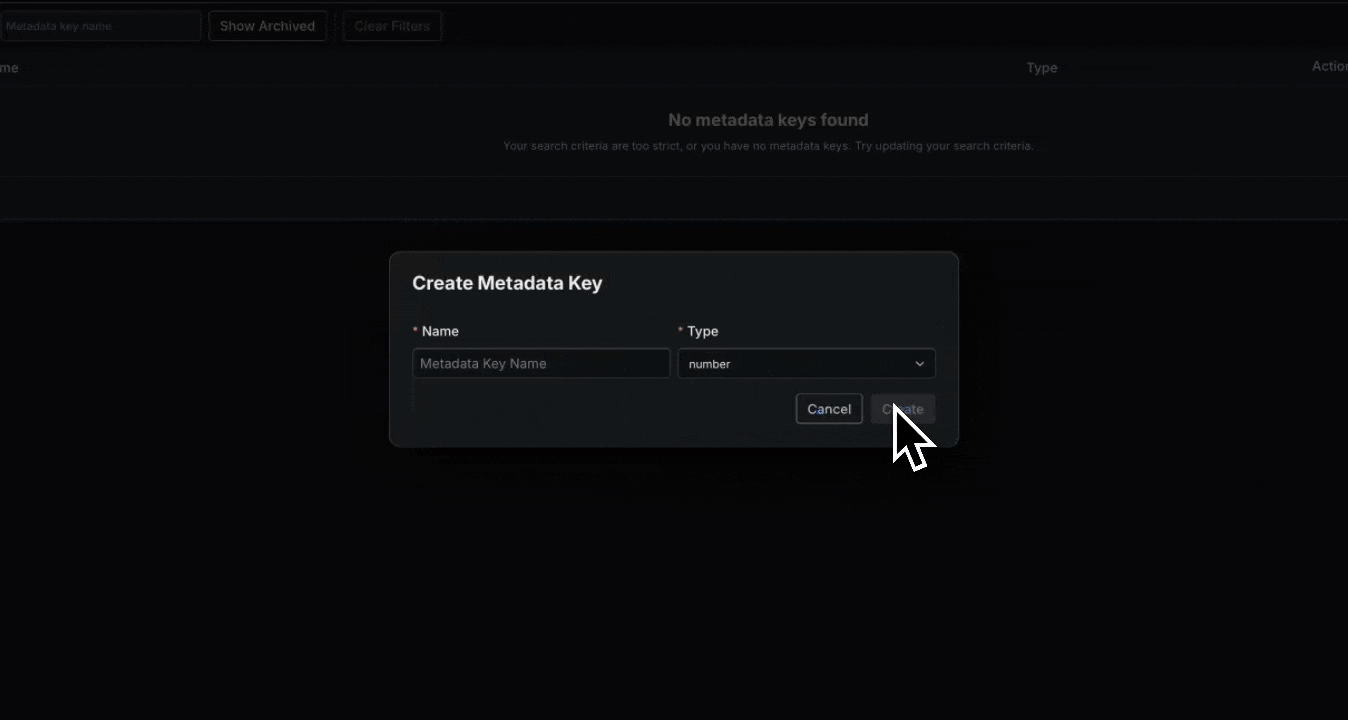
- Overview: Sift now supports user-defined Metadata,
allowing you to add structured key-value pairs to all resources including
Runs,
Assets,
Annotations,
Rules,
Reports,
Report Templates,
Campaigns,
Calculated Channels, and
User-defined Functions.
This provides a consistent way to describe and categorize resources beyond unstructured tags.
- See the documentation on User-Defined Metadata: Tutorial, Reference, and How-to guide.
New: Identity provider (IdP) (Beta) integration for scalable user management
- Overview: Sift now integrates with external Identity Providers (IdPs) that support push provisioning.
User and group changes in your IdP automatically synchronize to Sift, ensuring account information remains current without manual intervention.
- See the documentation on Identity provider (IdP): Tutorial, Reference, How-to guide.
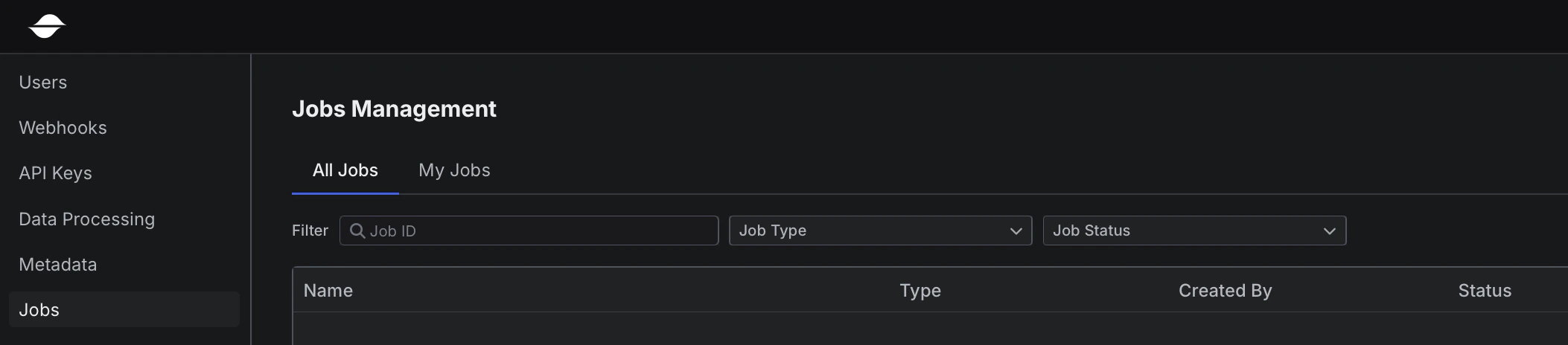
New: A dedicated Jobs page for easier monitoring and results tracking
- Overview: Sift now includes a dedicated Jobs page at
/manage/jobs. This page provides a central location to view all Jobs in your organization as well as your own Jobs, making it easier to monitor progress, manage execution, review results, and take actions such as canceling or retrying Jobs.
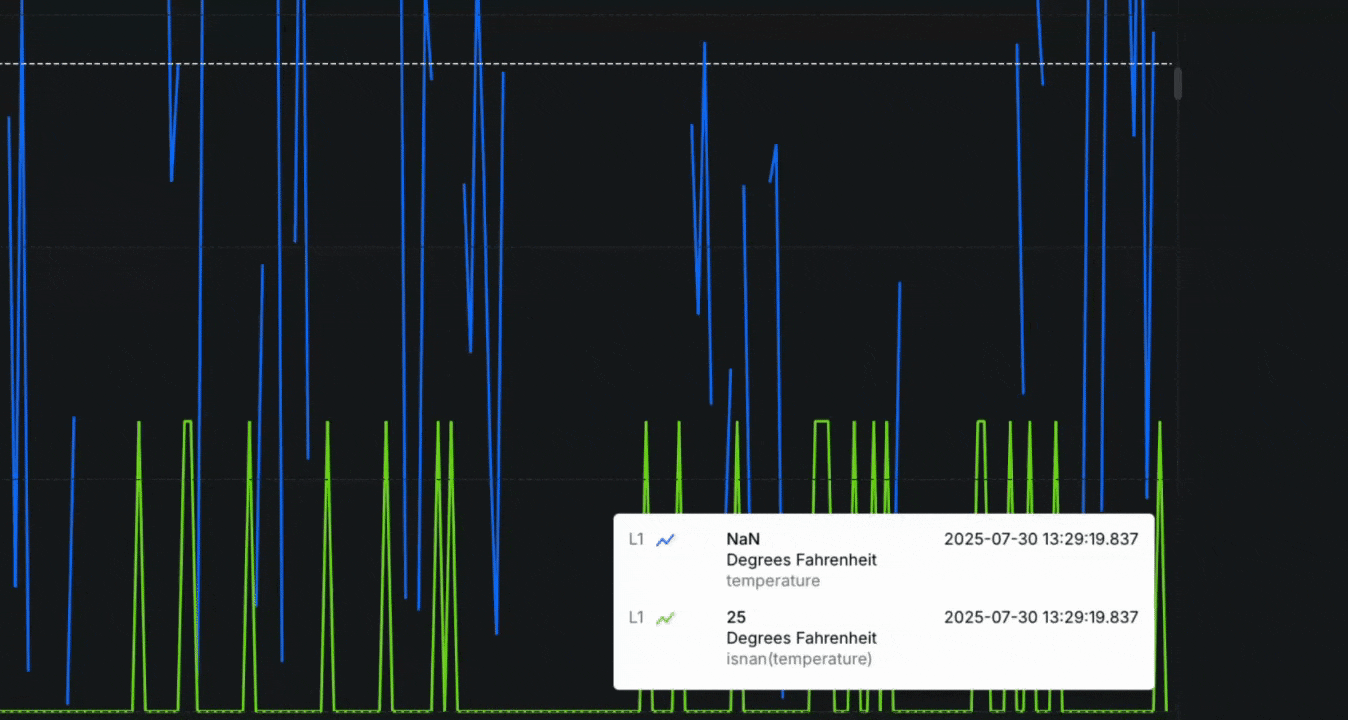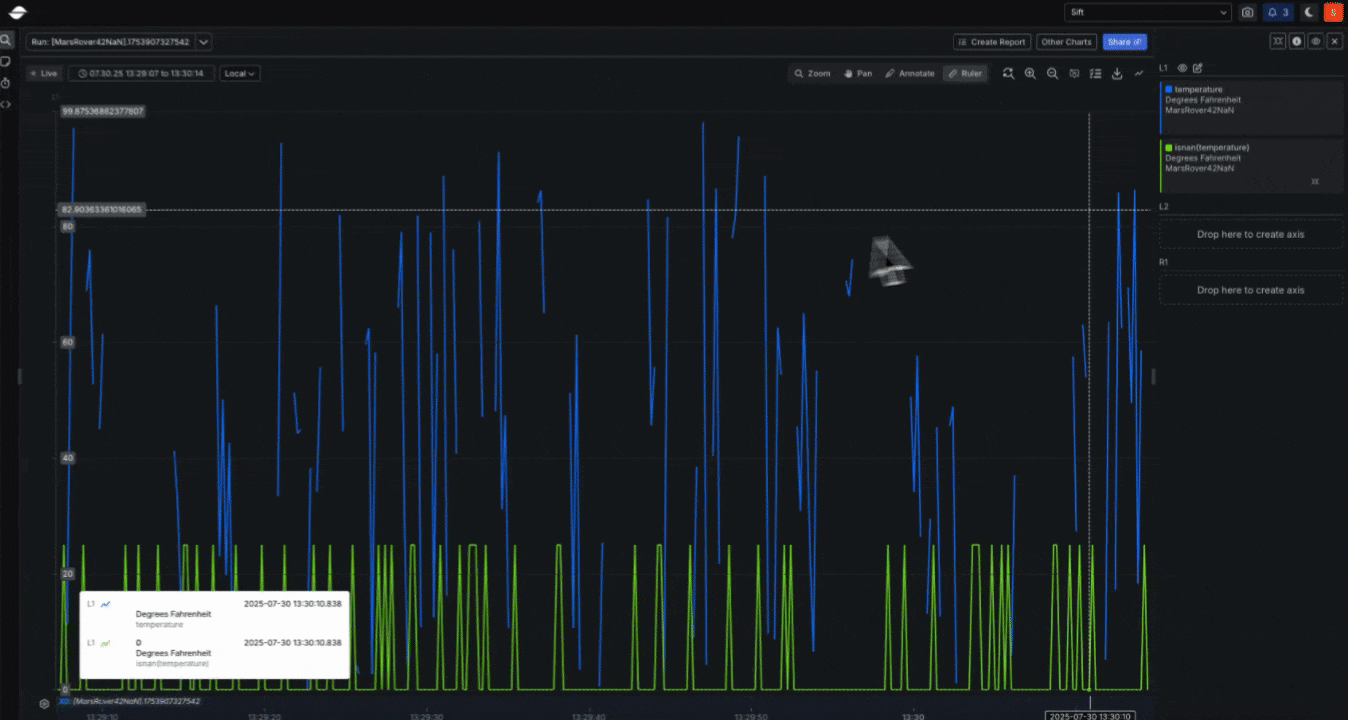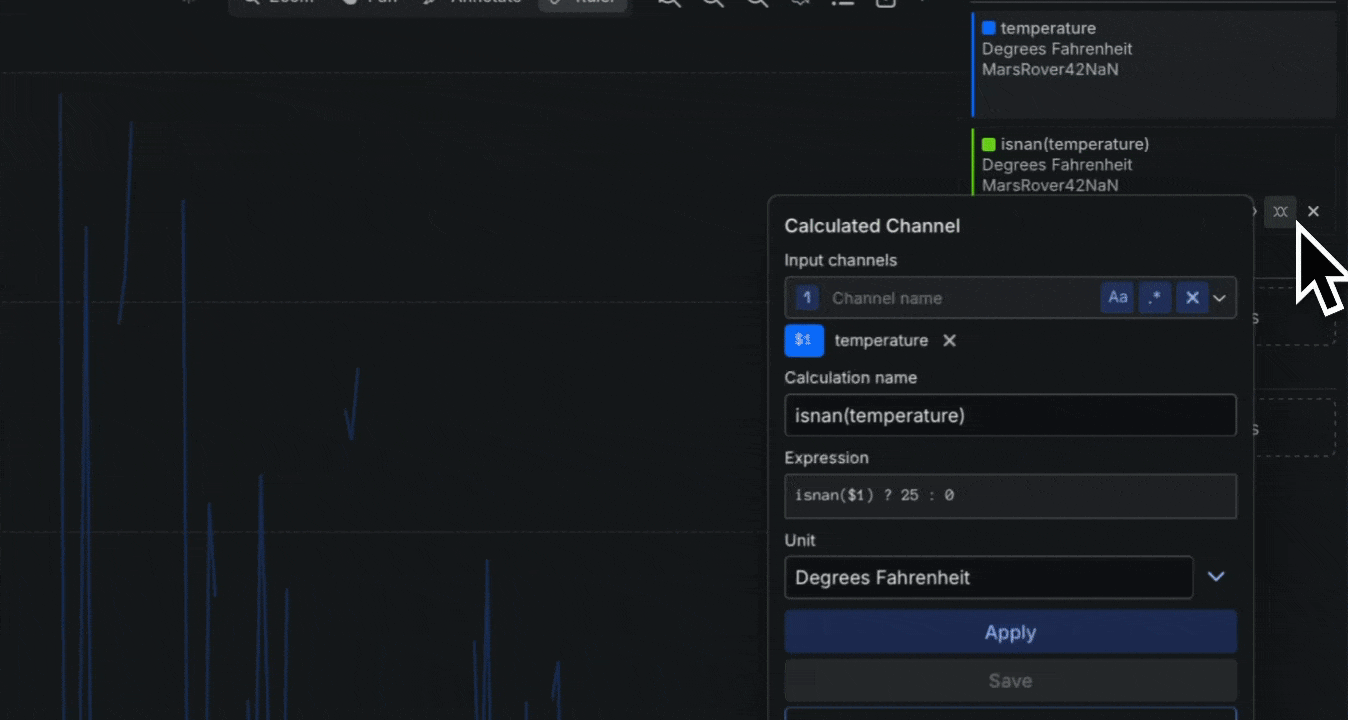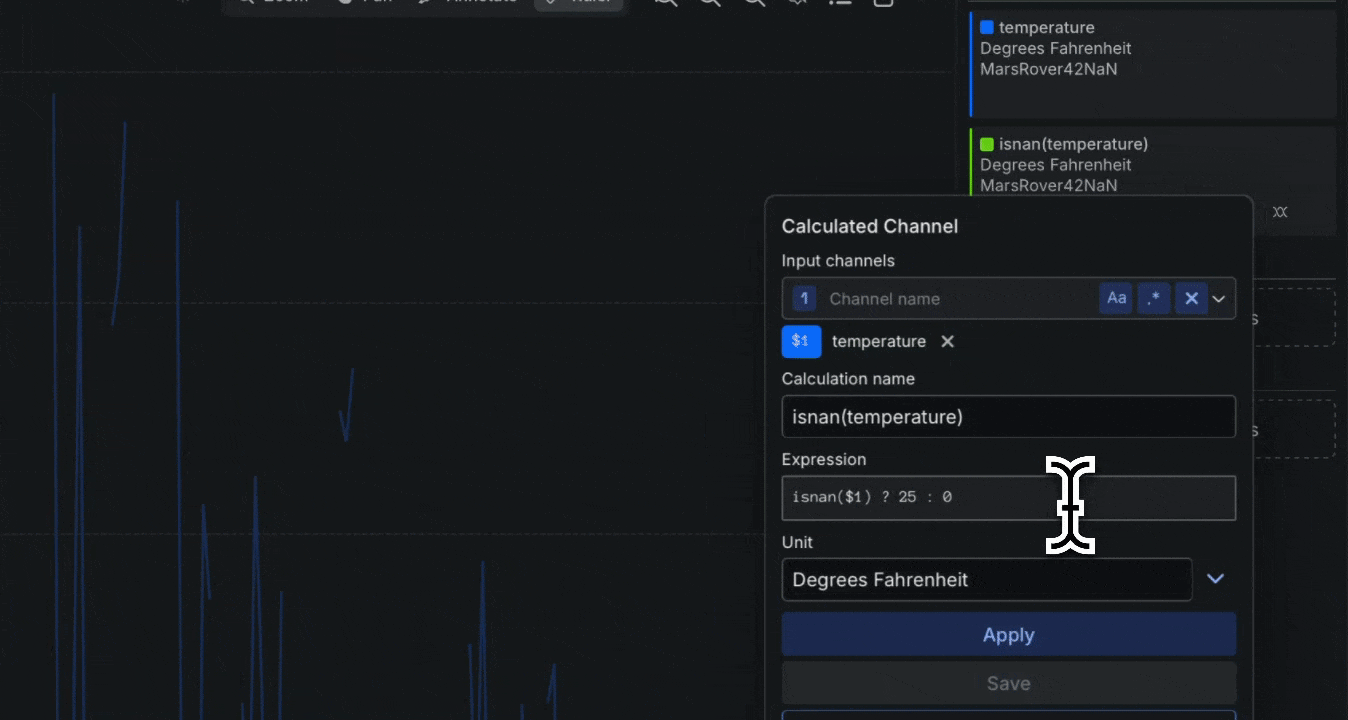
New: NaN and infinity handling for state-aware telemetry analysis
- Overview: Sift now supports ingestion and analysis of
NaN,+Infinity, and-Infinityvalues in float and double Channels. These values were previously filtered out and sent to the dead-letter queue (DLQ) but are now available in Rules, visualizations, and Calculated Channels. To ensure safe handling, new built-in functionsisnan,isinf, andisfiniteprovide precise control.
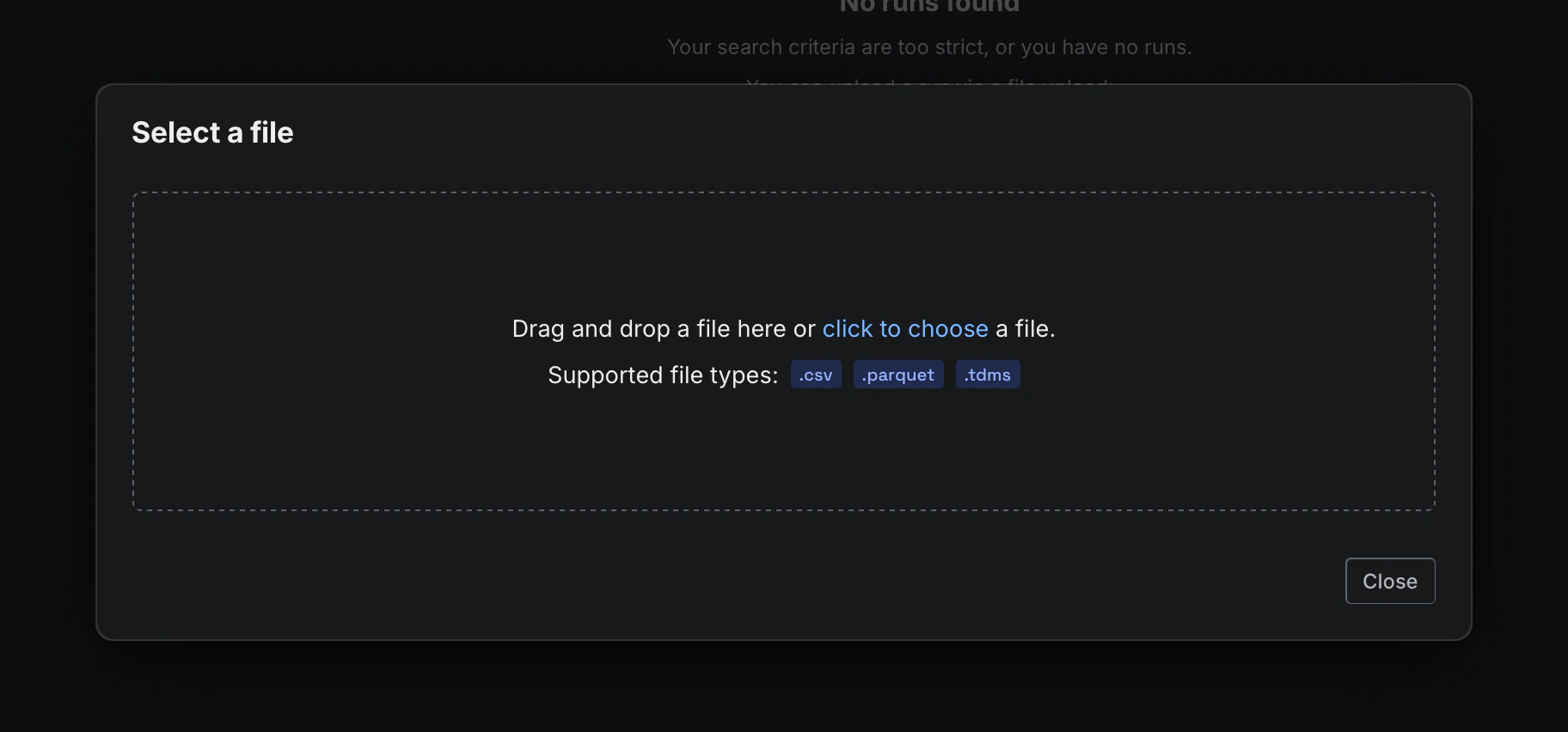
New: Parquet file support for telemetry ingestion in the UI and REST API (Beta)
- Overview: Sift now supports importing Parquet files through both the UI and the REST API.
Parquet files can be ingested directly, with each Channel represented as a column in a flat schema.
This makes it easier to bring telemetry from modern data pipelines into Sift.
- See the Parquet ingestion docs: Parquet uploads.
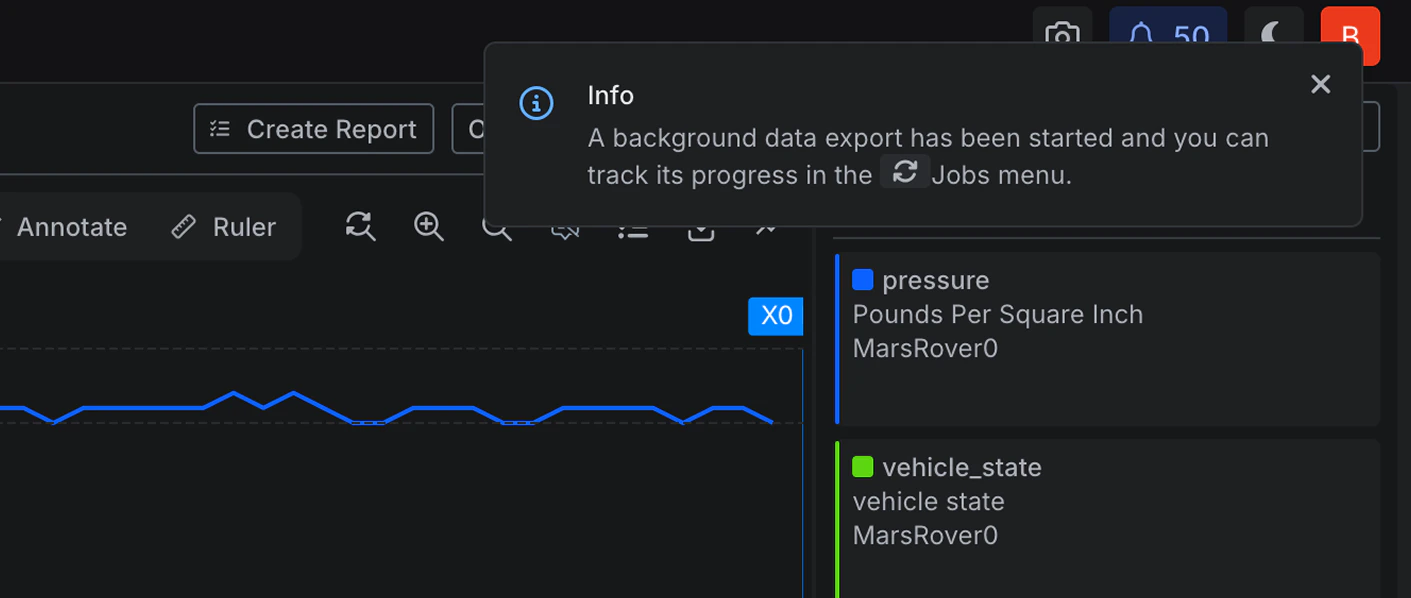
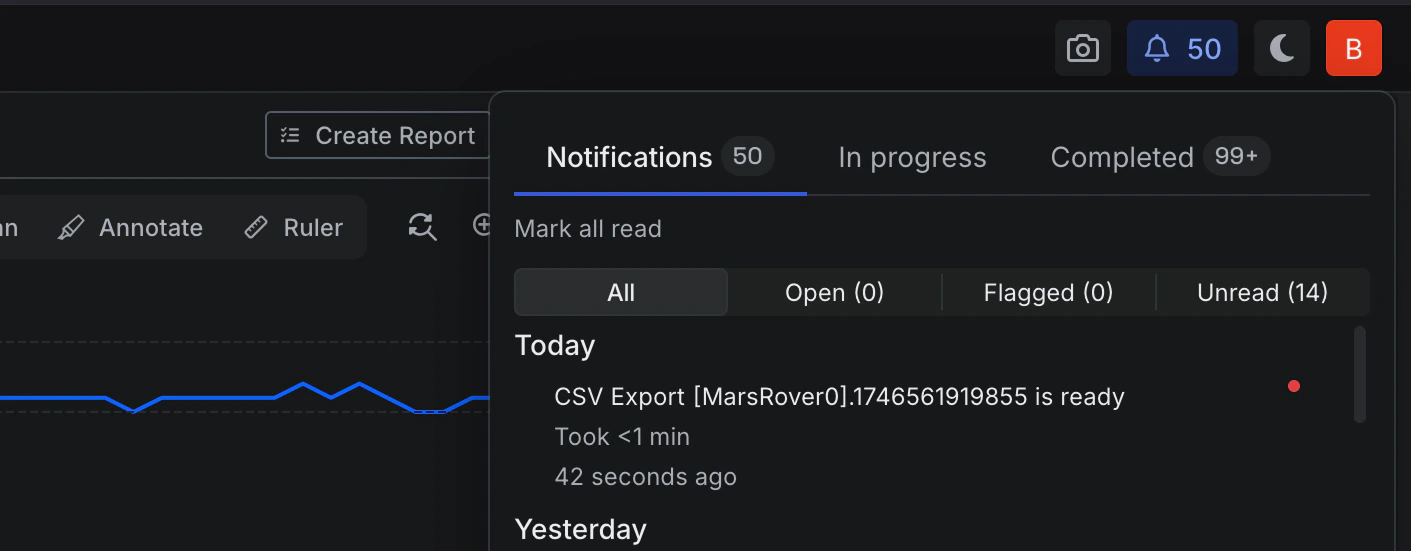
Improved: Support for 10 GiB exports with background notifications
- Overview: You can now export large volumes of data directly from the Explore page, whether viewing a Run or an Asset.
Exports are conducted in the background, and progress is visible in the Notifications dropdown and the Jobs page at
/manage/jobs. Once the export is complete, you will receive a notification and can download the results without needing to monitor the process. At this time, exports are supported up to 10 GiB per Job. This safeguard can be adjusted for specific customer needs.
Onboarding tutorial
- Overview: New to Sift, or onboarding a new teammate? Sift now includes a beginner tutorial that introduces the basics of the platform and walks through an end-to-end workflow using real telemetry data. This tutorial is designed to help new users understand Sift quickly and make onboarding easier for your team. Learn more.